
IT 세계의 후아
[논문]QLoRA: Efficient Finetuning of Quantized LLMs 본문
LLM Fine-Tuning에 대해 찾아보다 QLoRA를 접한 후 공부가 필요하다 느껴 관련 논문을 리뷰해보고자 한다
하지만 그 전에 'Quantization' 양자화에 대한 것도 공부해야 한다...(역시 공부는 공부를 부르고...)
들어가기에 앞서..
※ Quantization 양자화
정확하고 세밀한 단위의 입력값 → 단순화한 단위값(경량화)
즉, 정보를 표현하는 데 필요한 비트의 수를 줄여주는 것
ex) 인공신경망에서, 가중치 매개변수(weight) & 활성 노드 연산(activation function) 양자화
→ lower-bit의 수학연산 & 신경망 중간 계산값 양자화
※ 장단점
메모리 액세스↓ 연산량↓ 전력 효율성↑
but 압축되는 과정에서 채널의 수가 줄어드는 만큼 정보가 손실됨
정확도가 기존 모델에 비해 낮아질 수밖에 없음
∴ 모델을 손상시키지 않으면서 크기와 계산 비용을 줄이는 것이 목표
※ 종류
보통 tensorflow/pytorch의 파라미터는 32bit 부동소수점 연산, FP32(float32) 형태로 저장됨
이를 INT8/INT4 or FP8/FP4로 변환하게 됨
- Dynamic Quantization 동적 양자화
weight에 대해 먼저 양자화, 계산 수행 직전에 동적으로 양자화 됨
- Static Quantization 정적 양자화(Post Training Quantization)
훈련 이후 양자화 적용, parameter size가 큰 모델에서 효과적
- Quantization Aware Training 양자화 인식 교육
훈련 도중 양자화를 고려하여 모델을 조정가중치 양자화에 대한 학습(fake quantization node)을 포함
→ 원본 모델을 보다 양자화에 robust하게 만듦
보다 높은 accuracy
참고) 머신러닝 효율화 기법
양자화에 대해.. 그리고 관련 다른 기법들과도 헷갈려서(알던 것도 다 까먹었기 때문에)
더 가닥을 잘 잡기 위해 기본개념 복습!!
https://www.youtube.com/watch?v=2ySpRWvUShI
학습을 효율적으로 도와주는 기법
(1) 정규화 Normalization
데이터 x값 간에 차이가 너무 나면 정규화 과정이 필요함
가중치값을 조절하는 것은 굉장히 어렵고 비효율적임
표준정규분포를 따르도록 하는 StandardScaler(표준화)가 대표적
- Batch Normalization
대규모 학습 데이터셋을 작은 batch로 나누어 학습시킬 수 있음
예를 들어, batch size=15일 때 epoch(전체를 학습시키는 경우)=1이라면 batch size=5일 때 epoch=3, 1일 때 15가 됨
Batch별 같은 feature에 해당하는 값들(위치가 똑같은 값들)을 정규화
∴ batch size에 따라 성능이 좌우될 수 있
- Layer Normalization
하나의 batch/token의 값(한번에 들어온 값)을 정규화 → batch normalization보다 계산이 쉬움
트랜스포머에서 사용 多(트랜스포머 이후의 언어모델에 대부분 사용)
(2) 최적화 Optimization
- Gradient Descent
1) Batch Gradient Descent : 모든 데이터를 한번에 다 넣어서 가중치를 업데이트
2) Mini-Batch Gradient Descent : 데이터를 조금씩 쪼개서 업데이트
3) Stochastic Gradient Descent: batch size가 1인 경우, 하나의 배치당 가중치 업데이트 한 번 → 랜덤으로 가중치가 바뀔 수 있음
- Momentum
직전 가중치의 업데이트 방향을 반영
update(t) = r * update(t-1) + n∇w
W(t+1) = W(t) - update(t)
- RMSprop
학습률(learning rate)을 각 가중치별로 조정
GD가 상대적으로 큰 가중치에는 작은 학습률, 작으면 큰 학습률을 적용하여 수렴 속도를 향상시킴
∴ 가중치 업데이트가 많을수록 덜 학습을 하도록 함
- Adam(Adaptive moment estimator)
Gradient와 learning rate를 모두 조정하는 방식(모멘텀 + RMSprop)
(3) Dropout
과적합 해소를 위한 방식, regularization의 대표 방
모델을 만든 후 노드 몇 개를 의도적으로 삭제함
특정 노드의 의존도↓ 여러 개의 다른 신경망 모델을 앙상블하는 효과 ∴ 보다 일반화된 패턴
https://arxiv.org/pdf/2305.14314
오늘 읽어보려는 논문은 "QLoRA: Efficient Finetuning of Quantized LLMs"
(QLoRA를 알기 전에 LoRA를 공부해야 한다는 걸 잊고 시작한 나란 바보가 QLoRA 읽다 말고 LoRA를 읽은 리뷰
→ )
0. Abstract
- QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance
- backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters (LoRA)
- introduces a number of innovations
(a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights
(b) Double Quantization to reduce the average memory footprint by quantizing the quantization constants*
(c) Paged Optimizers to manage memory spikes
- provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation
- find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots.
* the quantization constant
- scaling factor로서 양자화 과정 가운데 값들이 어떻게 quantized format의 range에 scale될지를 결정함
- scaling 이후 값들의 상대적 차이를 유지시킴으로써, neural network의 행동을 보존시킴
- dequantization에서 정확하게 기존 값을 복원시키는 데에 사용됨
1. Introduction
- LLM 모델을 finetuning 하는 건 성능을 올리는 데에 효과적 but GPU 메모리를 필요로 하기에 굉장히 비쌈
- QLoRA를 통해, it is possible to finetune a quantized 4-bit model without any performance degradation
- QLORA’s efficiency enables us to perform an in-depth study of instruction finetuning and chatbot performance on model scales that would be impossible using regular finetuning due to memory overhead
- Guanaco(LLaMA 7B 기반 학습된 언어모델)를 학습시킴으로써 trained model에 관한 trend를 발견함
first, data quality is far more important than dataset size
second, dataset suitability matters more than size for a given task.
also provide a extensive analysis of chatbot performance that uses both human raters and GPT-4 for evaluation
- 토너먼트 형식으로 모델을 비교 & Elo scores(determine the ranking of chatbot performance)

2. Background
Block-wise k-bit Quantization
To ensure that the entire range of the low-bit data type is used, the input data type is commonly rescaled into the target data type range through normalization by the absolute maximum of the input elements, which are usually structured as a tensor*.
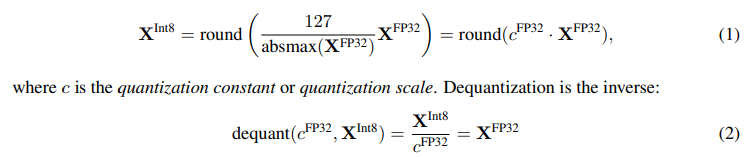
The problem with this approach is that if a large magnitude value (i.e., an outlier) occurs in the input tensor, then the quantization bins**—certain bit combinations—are not utilized well with few or no numbers quantized in some bins.
To prevent the outlier issue, a common approach is to chunk the input tensor into blocks that are independently quantized, each with their own quantization constant c. We chunk the input tensor X ∈ R b×h into n contiguous blocks of size B by flattening the input tensor and slicing the linear segment into n = (b × h)/B blocks. We quantize these blocks independently with Equation 1 to create a quantized tensor and n quantization constants ci .
즉, outlier 문제를 해결하기 위해 input tensor X를 flattening하고 크기가 B인 n개의 연속적인 블록으로 나누었고,
결국 각각의 블록이 양자화된 값(ci)을 만들어낸다는 뜻.
* tensor: 데이터의 배열 ex_scalar - vector - matrix - 3d tensor - nd tensor
** quantization bin: 양자화 함수 y=Q(x)에서 K-levd scalar quantizer는 k+1개의 decision level(d0, d1, ... ... , dk)과 K개의 output level(y0, y1, ... ... , yk)로 구성됨. 이때 di+1부터 di까지의 region을 quantization bin이라고 칭함.
Low-rank Adapters
Low-rank Adapter* (LoRA) finetuning is a method that reduces memory requirements by using a small set of trainable parameters, often termed adapters, while not updating the full model parameters which remain fixed.
LoRA augments a linear projection through an additional factorized projection.
+ LLM의 가중치 행렬에 근사화하는 두 개의 작은 행렬을 파인튜닝함

* adapter: 기존에 학습이 완료된 모델 사이사이에 학습가능한 작은 feed-forward networks를 삽입하는 구조
Memory Requirement of Parameter-Efficient Finetuning
While LoRA was designed as a 3 Parameter Efficient Finetuning (PEFT) method*, most of the memory footprint** for LLM finetuning comes from activation gradients and not from the learned LoRA parameters. ... ... gradient checkpointing is important but also that aggressively reducing the amount of LoRA parameter yields only minor memory benefits. This means we can use more adapters without significantly increasing the overall training memory footprint. As discussed later, this is crucial for recovering full 16-bit precision performance.
* PEFT: 사전학습된 LLM의 대부분의 파라미터는 고정, 필요한 일부 파라미터만 파인튜닝함 → 저장공간&계산능력↓ Catastrophic Forgetting 극복
** memory footprint: the amount of main memory that a program uses or ferences while running
3. QLoRA Finetuning
- QLoRA achieves high-fidelity 4-bit finetuning via two techniques we propose—4-bit NormalFloat (NF4) quantization and Double Quantization. Additionally, we introduce Paged Optimizers, to prevent memory spikes during gradient checkpointing from causing out-of-memory errors that have traditionally made finetuning on a single machine difficult for large models.
4-bit NormalFloat Quantization
- NormalFloat (NF) data type builds on Quantile Quantization which is an information-theoretically optimal data type that ensures each quantization bin has an equal number of values assigned from the input tensor. Quantile quantization works by estimating the quantile of the input tensor through the empirical cumulative distribution function.
즉, Quantile Quantization 기법은 누적분포 함수의 quantile을 추적하여 4-bit quantization 수행하도록 함
- SRAM quantile과 같은 fast quantile approximation algorithm을 사용하지만, large quantization errors for outliers가 발생하는 한계 O
- Expensive quantile estimates and approximation errors can be avoided when input tensors come from a distribution fixed up to a quantization constant. ... ... transform all weights to a single fixed distribution by scaling σ such that the distribution fits exactly into the range of our data type.
데이터 타입과 neural network weights를 [-1, 1]로 정규화함

Double Quantization
- the process of quantizing the quantization constants for additional memory savings.
- treats quantization constants c2FP32 of the first quantization as inputs to a second quantization.
- On average, for a blocksize of 64, this quantization reduces the memory footprint per parameter from 32/64 = 0.5 bits, to 8/64 + 32/(64 · 256) = 0.127 bits, a reduction of 0.373 bits per parameter.
4bit NFQ로 압축된 c2를 8bit로 한 번 더 압축시켜 c1을 계산함 → 파라미터 당 0.373bit의 리소스 절약
Paged Optimizers
- The feature works like regular memory paging* between CPU RAM and the disk. We use this feature to allocate paged memory for the optimizer states which are then automatically evicted to CPU RAM when the GPU runs out-of-memory and paged back into GPU memory when the memory is needed in the optimizer update step.
* memory paging: 프로세스의 논리 주소 공간을 page 단위로 자르고, 메모리의 물리적 주소 공간을 frame 단위로 자른 뒤, page를 frame에 할당하는 가상 메모리 관리 기법
QLoRA
- QLORA has one storage data type (usually 4-bit NormalFloat) and a computation data type (16-bit BrainFloat). We dequantize the storage data type to the computation data type to perform the forward and backward pass, but we only compute weight gradients for the LoRA parameters which use 16-bit BrainFloat*.

데이터를 4bit로 압축 저장하지만, weight gradient를 계산할 때는 16bit BrainFlot으로 압축 해제하여 수행함
* 16-bit BrainFloat(BF16): 32비트 부동 소수점 형식보다 정확도↓ 메모리 요구 사항↓ ∴모델 학습에 용이
cf) FP16 역시 메모리 사용량↓ 모델 훈련에는 일반적으로 FP32를 사용하고, 추론 단계에서 FP16을 사용해 연산 속도를 높이는 편.
≫ Mixed Precision: FP16, FP32를 혼합하며 모델학습에 사용하는 방식
4. QLoRA vs Standard Finetuing
- whether QLoRA can perform as well as full-model finetuning.
- want to analyze the components of QLoRA including the impact of NormalFloat4 over standard Float4.

- Our results consistently show that 4-bit QLORA with NF4 data type matches 16- bit full finetuning and 16-bit LoRA finetuning performance on academic benchmarks with wellestablished evaluation setups. We have also shown that NF4 is more effective than FP4 and that double quantization does not degrade performance.
5. Pushing the Chatbot State-of-the-art with QLoRA & 6. Qualitative Analysis
- we use the MMLU (Massively Multitask Language Understanding) benchmark to measure performance on a range of language understanding tasks. This is a multiple-choice benchmark covering 57 tasks including elementary mathematics, US history, computer science, law, and more.
- also test generative language capabilities through both automated and human evaluations.


7. Related Works
- Quantization of Large Language Models
- Finetuning with Adapters
- Instruction Finetuning
To help a pretrained LLM follow the instructions provided in a prompt, instruction finetuning uses input-output pairs of various data sources to finetune a pretrained LLM to generate the output given the input as a prompt.
- Chatbots
We do not use reinforcement learning, but our best model, Guanaco, is finetuned on multi-turn chat interactions from the Open Assistant dataset which was designed to be used for RLHF training*.
* RLHF training(Reinforcement Learning from Human Feedback): 사람의 피드백을 기반으로 ML 모델을 최적화함으로써, 자가학습을 보다 효율적으로 수행하는 ML 기법. AI 시스템이 더 인간적으로 보이도록 훈련시킴.
8. Limitations and Discussion
- we did not establish that QLORA can match full 16-bit finetuning performance at 33B and 65B scales.
- we did not evaluate on other benchmarks such as BigBench, RAFT, and HELM, and it is not ensured that our evaluations generalize to these benchmarks. On the other hand, we perform a very broad study on MMLU and develop new methods for evaluating chatbots.
- another limitation is that we only do a limited responsible AI evaluation of Guanaco.
- we did not evaluate different bit-precisions, such as using 3-bit base models, or different adapter methods
9. Broader Impacts
- Our QLORA finetuning method is the first method that enables the finetuning of 33B parameter models on a single consumer GPU and 65B parameter models on a single professional GPU, while not degrading performance relative to a full finetuning baseline. We have demonstrated that our best 33B model trained on the Open Assistant dataset can rival ChatGPT on the Vicuna benchmark.
- Another potential source of impact is deployment to mobile phones. We believe our QLORA method might enable the critical milestone of enabling the finetuning of LLMs on phones and other low resource settings.
cf)
https://aws.amazon.com/ko/what-is/reinforcement-learning-from-human-feedback/
https://huggingface.co/blog/4bit-transformers-bitsandbytes
https://jaeyung1001.tistory.com/entry/bf16-fp16-fp32%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90
https://devocean.sk.com/blog/techBoardDetail.do?ID=164779&boardType=techBlog
https://www.databricks.com/kr/blog/efficient-fine-tuning-lora-guide-llms
https://www.sciencedirect.com/topics/engineering/quantization-bin
https://guanaco-model.github.io/
https://pytorch.org/blog/introduction-to-quantization-on-pytorch/
https://pytorch.org/docs/stable/quantization.html
https://m.post.naver.com/viewer/postView.nhn?volumeNo=19437431&memberNo=20717909
'Coding > Study' 카테고리의 다른 글
| [AI]RAG 기본 이론&실습(3) (0) | 2024.08.05 |
|---|---|
| [error]ModuleNotFoundError: No module named 'pillow_heif' (0) | 2024.08.01 |
| [AI]RAG 기본 이론&실습(2) (0) | 2024.08.01 |
| [AI]RAG 기본 이론&실습(1) (0) | 2024.08.01 |
| [error]ValidationError: 1 validation error for ChatOpenAI (0) | 2024.08.01 |